


Recently, Microsoft introduced a new product called GitHub Copilot – and promptly received massive criticism from free software developers. Roughly speaking, it is a code completion feature based on machine learning, with the help of which programmers can implement trivial algorithms more easily. The reason for the outrage: Copilot was trained using freely licensed software uploaded to GitHub and sometimes reproduces verbatim copies of the input material, but is itself a commercial and proprietary product. This is supposedly not only unethical, but also violates so-called copyleft licences.
Copyleft is when an author places his work under a licence that allows free re-use exclusively on the condition that the licensee uses the same (or at least a comparable) licence for his derivative work. For example, if you wanted to re-use the source code from the social network Mastodon, you would also have to publish your own changes and additions and place them under the Affero GPL chosen by Mastodon.
Scraping isn’t copyright infringement
The argument that GitHub Copilot constitutes copyright infringement is based on the fact that copyleft-licensed works were used to train the “artificial intelligence”. While this is not wrong, the mere copying and analysis of code does not constitute copyright infringement in either the European Union or the US, as German internet activist and politician Felix Reda explains in a blog post (see also § 44b UrhG ). Otherwise, Reda argues, it would also constitute copyright infringement if one merely browsed the range of books in a bookshop.
Copilot outputs are no derivative works
Furthermore, the copyleft advocates’ claim implies that the output generated by GitHub Copilot is derivative work – meaning that it is protected by copyright and is protectable at all. However, this is not actually the case. It is true that Copilot would not be able to propose code without the training datasets, which means that it is absolutely dependent on copyrighted material in order to function at all.
Yet, this in no way makes newly generated code fragments derived works, as they are entirely new creations; after all, there is usually no intersection between the functionalities of the original and output codes. The training data is usually only used to artificially “understand” the syntax and semantics of the programming language, in order to subsequently be able to create output with a completely new task.
Copilot is not an author
As Lisa Käde explains in her dissertation “Creative Machines and Copyright” at the University of Freiburg, machine learning models are certainly worthy of copyright protection (cf. § 8 “Result of the third part”), but this does not apply in such a general way to their output. Copyright considerations in this context are extremely complex and always case-dependent.
In any case, it is certain that machines cannot create works and are therefore not authors in the meaning of copyright; according to § 2 (2) UrhG , only “personal intellectual creations” are protected. So the question arises whether a human being has contributed sufficiently to the creation of the AI outputs to be considered their author, or at least co-author.
It is true that human effort is very much necessary to configure an “artificial intelligence” in such a way that it delivers meaningful output. However, it is doubtful that it is extraordinarily ingenious to merely let an AI analyse countless software projects and that the creative expressiveness of this is high enough to justify copyright protection; after all, the essential part of the processing still happens behind the scenes, not in the command line. Nevertheless, this cannot be judged conclusively, since the details of the concrete implementation of GitHub Copilot are Microsoft’s trade secret.
GitHub doesn’t claim copyright in the outputs
Entire doctoral theses (like Lisa Käde’s) could be written on the question of whether the outputs of an AI are worthy of copyright protection, but in this specific case that is not even necessary, because Microsoft itself openly declares on its Copilot website that it does not claim any possible copyright to the output: “The code you write with GitHub Copilot’s help belongs to you, and you are responsible for it.”
Copilot outputs don’t reach the necessary level of creation
Due to the fact that the Copilot outputs are not works worthy of protection, certainly not derivative works, and GitHub waives possible copyrights anyway, the only option left for the alleged copyleft infringement is the unmodified copy of parts of the input data.
But even then, due to their small size, Copilot’s code proposals do not even come close to the level of artistic creation that would be necessary to justify copyright protection. According to GitHub, in 99% of cases the output is shorter than 150 characters. Such short excerpts are by no means individual enough to stand out from the crowd and constitute intellectual property within the meaning of § 69a (3) UrhG . In most cases, the completion proposals are merely direct, obvious, generic, unadorned transformations of a simple algorithm into a concrete programming language.
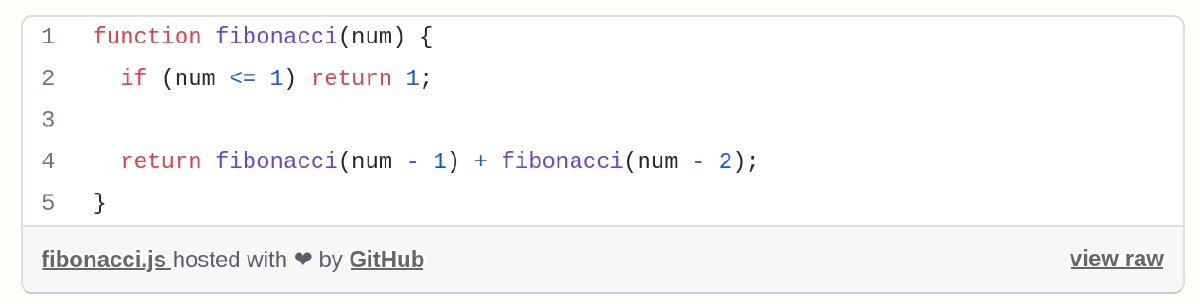
For example, this 100-character code section is the direct implementation of the recursive definition of the Fibonacci numbers and is in no way protected by copyright, since it is the simplest possible variant that anyone could and would realise without any effort of intelligence or creative achievement. The concept of the Fibonacci numbers itself is also in the public domain, as it is neither protectable as the underlying idea of the computer program nor does it fall into any of the categories of independent works under § 2 UrhG .
The complexity of AI is irrelevant
Furthermore, it should be noted that the complexity of the “artificial intelligence” behind the outputs has no relevance for their copyright protection. In 1986, the regional court of Berlin clarified:
The purely technical performance, which anyone with average abilities could also achieve, even if it is based on creditable diligence and solid skill, is outside the scope of protection.”
in 16 O 72/86
Do licences apply here at all?
However, let us take a step back and ask ourselves whether GitHub would basically have to abide by the licences chosen by the developers in order to be allowed to continue using their works. At first glance, this may seem to be the case; after all, the programmers have a copyright to their software, which is why only the chosen licence can create exceptions in the first place.
Though, the fact must not be overlooked that when you register with GitHub, you have to agree to their terms of service which explicitly state:
“Because you retain ownership of and responsibility for Your Content, we need you to grant us – and other GitHub Users – certain legal permissions. […] We need the legal right to do things like host Your Content, publish it, and share it. You grant us and our legal successors the right to store, archive, parse, and display Your Content, and make incidental copies, as necessary to provide the Service, including improving the Service over time.” GitHub Terms of Service, § 3
This arrangement is an alternative to licensed re-use for GitHub, which is why it is completely irrelevant whether a developer on GitHub demands compliance with his copyleft provisions: That customer has already granted GitHub the necessary usage rights by agreeing to the terms of use and has no legal claims against GitHub anymore.
Commercial re-use is not unethical
Now that it has been clarified that GitHub Copilot does not constitute copyright infringement of the training data for various reasons, let us turn to the question of whether it is at least ethically reprehensible, as the copyleft advocates are so fond of claiming. Their argument is somewhat understandable: Unpaid volunteers toil by the sweat of their brow, only for a billionaire, unscrupulous, profit-oriented company to later create a commercial product out of their beloved projects, without at least publishing the source code and thus giving something back to the free software community.
In fact, it is quite unjust for someone to redistribute an application for the sole purpose of making a profit without having made any substantial contribution of his own. Such behaviour is also not excluded without reason by the For Good Eyes Only Licence (which allows commercial re-use only for substantial works of which the licensed work is merely a component).
However, it would be anything but expedient to categorically condemn commercial re-use. What is wrong about someone creating a new product with the help of external components that provides a useful solution to a real problem, and demanding financial compensation for their efforts?
If the issue is that the developer of the original work does not share in the profits, it is easy to counter that, on the one hand, he is free to monetise his own work as well and, on the other hand, he always had the option of realising the work created by the licensee himself. There is no reasonable cause why only the original author should be entitled to copyright protection.
However, if the question is that profit is generally unethical, the answer must be that such an attitude is simply incompatible with modern society. Anyone who wants to be able to pay rent, electricity, water, heating and bills is dependent on an income; the unrealistic ideas of a few moralisers do not change this in the slightest. Anyone who has a problem with the concept of capitalism is much better off in politics than in the free software community.
Scraping is not unethical but a cornerstone of software freedom
Furthermore, the question arises as to what is unethical about having publicly accessible works analysed by AI. Regardless of the fact that there is no copyright infringement here, there is nothing ethically wrong with it, considering the fact that studying the source code is an essential pillar of software freedom. Those who criticise GitHub for studying their source codes have probably forgotten why they put them under a free licence in the first place. As a reminder, here are the four software freedoms again:
- The freedom to run the program as you wish, for any purpose (freedom 0).
- The freedom to study how the program works, and change it so it does your computing as you wish (freedom 1). Access to the source code is a precondition for this.
- The freedom to redistribute copies so you can help others (freedom 2).
- The freedom to distribute copies of your modified versions to others (freedom 3). By doing this you can give the whole community a chance to benefit from your changes. Access to the source code is a precondition for this. Those who do not want to grant such elementary freedoms should simply make their software proprietary and not publish its source code. Free Software Foundation
Double standards at their best
Moreover, it is downright absurd that copyleft advocates on the one hand attack users of ethical licences (such as the For Good Eyes Only Licence) for not wishing to tolerate human rights violations, for example, and call for tolerance of intolerance, but are themselves immediately outraged when someone they just do not fancy makes use of their own works.
Copyleft promotes monopoly
In addition to the countless legal mistakes made by many developers, the Copilot affair also demonstrates that copyleft licensing may be well-intentioned, but does not achieve its goals. Due to the fact that copyleft requires the re-licensing of the protected work under the exact same or at least a comparable licence, one must inevitably ask on what legal basis copyleft licensees upload their derivative works to third-party platforms.
Of course, they themselves have the right to publish their forks. But strictly speaking, copyleft licences do not typically provide exceptions for granting full usage rights to a code hosting provider, as is the case when accepting GitHub’s terms and conditions. In order to comply with the copyleft provisions, one would actually have to negotiate individual terms and conditions with GitHub that include the conditions stipulated in the original licence.
If one does not want to commit copyright infringement and risk a lawsuit, one should refrain from publishing forks on third-party platforms. Doing so on the same website, on the other hand, would not be a problem; after all, the author of the original work would then have already agreed to the provider’s terms and conditions himself, which is why the granting of usage rights by the licensee would not make any difference.
However, this circumstance promotes monopolies immensely, as we can see from the example of GitHub. If one wants to use copyleft software uploaded to GitHub in a legally secure way, one is practically forced to use GitHub yourself instead of another platform. Due to this circumstance, it must be clearly stated that copyleft, as opposed to permissive licensing, entails massive legal problems and thus unnecessarily hinders the development of free software.
Of course, it can be argued that every developer would simply have to host his own Git repo server to avoid the third-party problem, but this is simply absurd given the disproportionate maintenance effort, expertise required and high server rental costs.
Another argument, on the other hand, is not so meaningless: Those who place their code under a copyleft licence send the political message that they support free software. Those who do so cannot aim to prevent others from exercising their software freedoms – by not allowing them to upload the source code to third-party providers. Moreover, the usage rights granted to the hosting provider are often limited to actually providing the services offered. And it should also be taken into account that such practices are de facto common-place. In this respect, it would be a restriction of copyright that is on the one hand expected and on the other hand bearable.
On the other hand, one should not rely on such an argumentation, because as long as this is not explicitly regulated by law (or at least a precedent exists), it is simply an illegal copyright infringement. Moreover, it should be noted that free software often involves several jurisdictions whose legal situations can obviously differ.
Software freedom means freedom of licence choice
Furthermore, the enforceability of copyleft licences is directly linked to strict copyright law, because anyone who demands re-licensing under the same conditions must enforce this with the help of traditional copyright, the circumvention or even abolition of which is actually the goal of free licensing.
Software freedom should also mean the freedom of the licensee to withdraw his adaptation from copyright by means of free licensing. Copyleft clauses, however, deny this freedom by making use of copyright themselves.
Stricter copyright law would only bring disadvantages
The matter becomes particularly absurd, however, when copyleft advocates call for even stricter copyright law, only for even the smallest snippets of code to already constitute intellectual property and thus also fall under the re-licensing clauses. However, they do not understand that copyleft would not be necessary at all if copyright did not guarantee such a “high degree of exclusive control over intellectual creations in the first place”, as Felix Reda puts it.
As he rightly points out, a stricter copyright law would also primarily strengthen established rights – and not the copyleft principle. For example, press publishers have long been lobbying for a stronger ancillary copyright, according to which even the titles of newspaper articles, i.e. even the shortest phrases and sentence fragments, would be protected by copyright. This would mean that search engines, for example, would have to pay to display headlines and descriptive texts in search results.
Big companies like Google, Meta or Twitter can easily afford such payments. But what about non-commercial services like the free social medium Mastodon or the open-source Signal Messenger? What about XMPP and email clients that some volunteer has just developed in his spare time? They would have to dispense with essential functions like link previews.
In January 2022, the regional court in Hamburg ruled (308 O 130/19 ) that browser ad blockers do not constitute “unauthorised copying and/or reworking” of copyright-protected websites. In line with the copyleft advocates’ ideas of stricter copyright protection, it would therefore possibly be forbidden in future to use additional software to protect oneself from intrusive advertising and privacy-invading trackers.
How we should license our works instead
Copyleft only brings unwanted problems. Its enforcement requires stricter copyright law, restricts licensees in their software freedom and causes serious legal problems when creating forks.
Instead, we should rather just use one of the conventional permissive licences for our works, such as the MIT licence . Not only is it very easy to understand, but it also leaves the details of re-licensing up to the licensee.
For all those who want to face up to their responsibility as software developers and set a sign against injustice in the world, there is also the option of ethical licensing. In addition to the obvious, i.e. war crimes and human rights violations, the For Good Eyes Only Licence, for example, also prohibits things like privacy violations or fake news and excludes environmental offenders from re-use.
A particular advantage of the For Good Eyes Only Licence is that it also does not contain a copyleft clause. In order to be able to enforce the ethical rules of conduct against third-party licensees too, the components of the original work must always remain under the original licence; but regarding changes and additions the licensee can choose any licence he likes. This regulation is called “weak copyleft” and is loosely based on the Mozilla Public Licence.
Why we should still #GiveUpGitHub
Despite the absurd, unrealistic vilification of the Copilot function, it must be said in conclusion that the general criticism of GitHub as a hosting provider is nevertheless justified – for the following four reasons.
First, it makes no sense that we use a proprietary platform for our free software. We should rather work for the dissemination of free software; we can do this by already using free tools for the development of our works.
Second, it is anything but sensible to allow such a powerful quasi-monopoly. What would we do if Microsoft shut down GitHub overnight? Many people would certainly get their hands wet if GitHub were unavailable for even a few hours due to a power outage or the like. Moreover, a monopoly potentially opens the door to censorship.
Third, we exclude from contributing to our free software all those who, for whatever reason, cannot or do not wish to register on GitHub. Some may be affected by restrictive US export regulations, others fear for their privacy.
Fourth, as the parent company of GitHub, Microsoft is an unscrupulous producer of ad-tracking malware and a morality-free collaborator with US intelligence agencies. We should not support these unethical practices by using Microsoft’s products.
Instead, we should register on Gitlab or Gitea servers: Both platforms are open source themselves. This makes privacy-friendly and censorship-resistant self-hosting possible. The more developers are willing to leave GitHub, the more public Gitlab and Gitea servers will be opened. In addition, Forgejo are already working on a standard with which Git-based code hosting servers should be able to communicate with each other (analogous to e-mail or ActivityPub). Thanks to such federation, one would only have to register on one platform and could still contribute to Git repos on all the other servers.
Particularly recommended is the German Git instance Codeberg , whose key advantage over other servers is the Codeberg Pages feature – a fantastic replacement for GitHub Pages.
Let us hope that as soon as possible a comprehensive rethinking will take place in the free software community and that people will finally realise how absurd it is that the essential tool of our cooperation is not itself free software.
 Optimised for
Mozilla Firefox
Optimised for
Mozilla Firefox
 Onionize with
Tor Hidden Service
Onionize with
Tor Hidden Service
 Follow on
Mastodon
Follow on
Mastodon
 Please donate
Against the War
Please donate
Against the War

