


Kürzlich hat Microsoft ein neues Produkt namens GitHub Copilot auf den Markt gebracht – und prompt massive Kritik vonseiten etlicher Entwickler freier Software einstecken müssen. Grob gesagt, handelt es sich um eine Code-Vervollständigungs-Funktion auf Grundlage eines großen Sprachmodells, mithilfe derer Programmierer einfache Algorithmen effizienter implementieren können. Der Grund für die Entrüstung: Copilot ist (auch) auf bei GitHub veröffentlichter freier Software trainiert worden und gibt gelegentlich eins zu eins Ausschnitte des Quellmaterials wieder, allerdings obwohl Copilot selbst ein kommerzielles, proprietäres Produkt ist. Dies sei nicht nur unethisch, sondern verletze auch sogenannte Copyleft-Lizenzen.
Copyleft bedeutet, dass ein Autor sein urheberrechtlich geschütztes Werk unter eine Lizenz stellt, die freie Weiterverbreitung ausschließlich unter der Bedingung erlaubt, dass der Lizenznehmer seine abgeänderte Version (auch „Derivat“ oder „abgeleitetes Werk“ genannt) unter dieselbe bzw. eine vergleichbare Lizenz stellt. Wollte man beispielsweise den Quellcode des sozialen Netzwerks Mastodon weiterverwenden, so müsste man veränderte oder hinzugefügte Passagen unter der von Mastodon gewählten Affero-GPL-Lizenz veröffentlichen.
Scraping stellt keine Urheberrechtsverletzung dar
Das Argument, GitHub Copilot seine eine einzige riesengroße Urheberrechtsverletzung, basiert auf der Tatsache, dass Copyleft-lizenzierte Werke zum Training der „künstlichen Intelligenz“ verwendet wurden. Zwar ist das nicht falsch, doch das bloße Kopieren und Analysieren von Code – zumindest im Rahmen des Text- und Data-Minings verletzt kein Urheberrecht – weder in der Europäischen Union noch in den USA, wie der deutsche Internetaktivist und Politiker Felix Reda in einem Artikel erklärt (siehe auch § 44b UrhG ). Ansonsten, argumentiert Reda, würde es auch eine Urheberrechtsverletzung darstellen, das Sortiment einer Buchhandlung zu durchstöbern.
Copilot-Ausgaben sind keine abgeleiteten Werke
Darüber hinaus implizieren die Copyleft-Befürworter, dass die von GitHub Copilot generierten Ausgabetexte abgeleitete Werke seien – was bedeuten würde, dass sie urheberrechtlich geschützt und überhaupt schützbar seien. Allerdings ist das nicht der Fall. Es stimmt durchaus, dass Copilot ohne die Trainingsdatensätze nicht in der Lage wäre, Code vorzuschlagen; insofern ist Copilot sehr wohl abhängig von urheberrechtlich geschütztem Material, um überhaupt funktionieren zu können.
Allerdings macht das in keiner Weise die frisch generierten Codefragmente zu abgeleiteten Werken, da es sich um neuen Code handelt; schließlich gibt es meist keine Schnittmenge zwischen dem Trainingsmaterial und der Ausgabe. Die Datensätze werden regelmäßig nur dazu verwendet, die Syntax und die Semantik der Programmiersprache künstlich zu „verstehen“, um völlig neue Ergebnisse zu erzeugen.
Copilot ist kein Urheber
Wie Lisa Käde in ihrer Dissertation „Kreative Maschinen und Urheberrecht“ an der Universität Freiburg darlegt, sind Machine-Learning-Modelle durchaus urheberrechtlich schutzfähig (siehe § 8 „Ergebnis des dritten Teils“), aber dies trifft nicht allgemein auf deren Ausgabe zu. Urheberrechtliche Erwägungen in diesem Kontext sind äußerst komplex und immer fallabhängig.
Jedenfalls ist sicher, dass Maschinen nicht zu eigenen kreativen Leistungen befähigt sind und damit keine Urheber im Sinne des Urheberrechts sein können, denn gemäß § 2 Abs. 2 UrhG sind nur „persönliche geistige Schöpfungen“ schutzfähig. Entsprechend stellt sich die Frage, ob ein Mensch hinreichend zur Kreierung der KI-Ausgaben beigetragen hat, um als deren Urheber (oder zumindest Miturheber) zu gelten.
Sehr wohl sind menschliche Anstrengungen nötig, um eine „künstliche Intelligenz“ so zu konfigurieren, dass sie sinnhafte Ausgaben produziert. Jedoch ist zweifelhaft, ob es außerordentlich originell ist, eine KI unzählige Softwareprojekte analysieren zu lassen, und ob die dafür nötige kreative Leistung und Ausdruckskraft hinreichend ausgeprägt sind, um von Urheberrechtsschutz ausgehen zu können; schließlich passieren die wesentlichen Verarbeitungsschritte hinter den Kulissen und nicht in der Kommandozeile. Nichtsdestotrotz kann dies nicht abschließend bewertet werden, da die Implementierungsdetails von GitHub Copilot ein Firmengeheimnis von Microsoft sind.
GitHub erhebt keine Urheberrechtsansprüche auf die Ergebnisse
Ganze Doktorarbeiten (wie die von Lisa Käde) könnten der Frage gewidmet werden, ob die Ausgaben einer KI urheberrechtlichen Schutz genießen können, doch in dieser Diskussion ist das gar nicht nötig, denn Microsoft selbst erklärt offen auf der eigenen Copilot-Website , dass man keine Urheberrechtsansprüche auf die Ausgaben erhebe: „Der Code, den du mit GitHub Copilots Hilfe schreibst, gehört dir, und du bist für ihn verantwortlich“ (übersetzt).
Copilot-Ausgaben erreichen nicht die künstlerische Schöpfungshöhe
Aufgrund der Tatsache, dass Copilots Ausgaben keine schutzfähigen Werke sind – und sicherlich keine abgeleiteten Werke – und dass GitHub jegliche Urheberrechte bestreitet, bleibt nur noch eine Option übrig, um Urheberrechtsverletzungen begründen zu können: unveränderte Wiedergabe von Teilen der Trainingsdaten.
Doch selbst wenn es zu solcher Eins-zu-eins-Reproduktion käme, kommen Copilots Code-Vorschläge aufgrund ihrer Kürze nicht einmal in die Nähe der künstlerischen Schöpfungshöhe, die für Urheberrechtsschutz zu erreichen wäre. Laut GitHub seien in 99 % der Fälle die Ausgaben kürzer als 150 Zeichen. Solch kurze Ausschnitte sind keineswegs originell genug, um aus der Masse herauszustechen und geistiges Eigentum im Sinne des § 69a Abs. 3 UrhG darzustellen. In den meisten Fällen stellen die Vervollständigungsvorschläge eine direkte, offensichtliche, generische, nicht ausgeschmückte Formulierung eines einfachen Algorithmus in einer konkreten Programmiersprache dar.
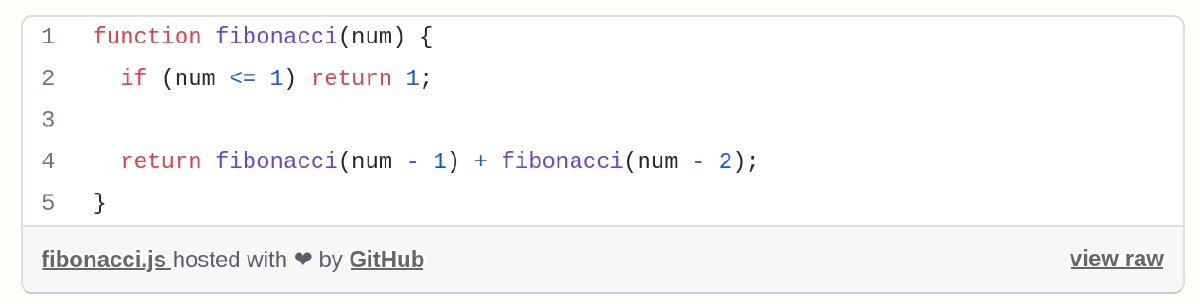
Beispielsweise ist dieser 100-Zeichen-Code-Abschnitt die direkte Implementierung der rekursiven Definition der Fibonacci-Zahlen und ist in keiner Weise urheberrechtlich geschützt, da es sich um die einfachstmögliche Variante handelt, die jeder ohne irgendeine geistige Anstrengung oder kreative Leistung realisieren könnte (und würde). Das Konzept der Fibonacci-Zahlen an sich ist ebenfalls gemeinfrei, da es weder als die dem Computerprogramm zugrunde liegende Idee schutzfähig ist noch in irgendeine Kategorie persönlicher Schöpfungen nach § 2 UrhG fällt.
Die Komplexität der KI ist irrelevant
Weiterhin sollte Beachtung finden, dass die Komplexität der „künstlichen Intelligenz“ hinter den Ausgaben keine Relevanz für den Urheberrechtsschutz hat. 1986 stellte das Landgericht Berlin klar:
Die rein handwerkliche Leistung, die jedermann mit durchschnittlichen Fähigkeiten ebenso zustande brächte, mag sie auch auf anerkennenswertem Fleiß und auf solidem Können beruhen, liegt außerhalb der Schutzfähigkeit.“
in 16 O 72/86
Sind Lizenzen in diesem Kontext relevant?
Gegenstand der Betrachtung sei nun die Frage, ob GitHub dazu verpflichtet ist, die Bedingungen der von den Entwicklern gewählten Lizenzen zu befolgen hat, um die betroffenen Werke rechtmäßig verwenden zu dürfen. Dem ersten Eindruck nach sollte das der Fall sein, haben die Programmierer doch das Urheberrecht an ihrer Software inne; und nur durch eine Lizenz können überhaupt Nutzungsrechte eingeräumt werden.
Allerdings darf die Tatsache nicht ignoriert werden, dass den Nutzungsbedingungen zustimmen muss, wer sich bei GitHub registriert. Dort ist explizit zu lesen:
„Weil Sie das Eigentum an und die Verantwortlichkeit für Ihre Inhalte behalten, müssen Sie uns – und anderen GitHub-Nutzern – bestimmte Nutzungsrechte einräumen. […] Wir benötigen das Recht, bestimmte Dinge zu tun, wie z.B. Ihre Inhalte zu hosten, zu veröffentlichen und zu teilen. Sie erteilen uns und unseren Rechtsnachfolgern das Recht, Ihre Inhalte zu speichern, zu archivieren, zu parsen und anzuzeigen sowie gelegentlich Kopien anzufertigen, soweit dies für die Bereitstellung des Dienstes erforderlich ist, einschließlich der Verbesserung des Dienstes im Laufe der Zeit.“ Abs. 3 GitHub-Nutzungsbedingungen (übersetzt)
Diese Vereinbarung bietet GitHub eine Alternative zu an Freie-Software-Lizenzen gebundene Weiterverbreitung, weshalb es völlig irrelevant ist, ob ein GitHub-Kunde GitHubs Einhaltung von Copyleft-Bedingungen einfordert: Jener Kunde hat durch seine Zustimmung zu den Nutzungsbedingungen GitHub bereits die nötigen Nutzungsrechte eingeräumt und hat daher keinen Anspruch gegen GitHub mehr.
Kommerzielle Weiterverwendung ist nicht (per se) unethisch
Nachdem nun klargestellt ist, dass und wieso es keine Urheberrechtsverletzung am Trainingsmaterial darstellt, GitHub Copilot zu verwenden, ist nun zu erörtern, ob die Verwendung zumindest moralisch verwerflich ist, wie die Copyleft-Enthusiasten zu betonen nicht verlegen werden. Ihr Argument ist zumindest ansatzweise verständlich: Unbezahlte Freiwillige malochen im Schweiße ihres Angesichts, nur damit ein milliardenschweres skrupelloses, profitorientiertes Unternehmen später ein kommerzielles Produkt aus ihrem geliebten Projekt herstellen, ohne auch nur den Quellcode zu veröffentlichen und so der Freie-Software-Gemeinschaft wenigstens immaterielle Werte zurückzugeben.
Es ist wahrlich recht ungerecht, wenn jemand ein Programm allein zum Zweck der Gewinnerzeugung weiterverbreitet, ohne irgendwelche eigenen substanziellen Beiträge geleistet zu haben. Solches Verhalten ist nicht ohne Grund durch die For-Good-Eyes-Only-Lizenz ausgeschlossen, welche kommerzielle Verwendung nur für umfangreiche Werke erlaubt, in denen das lizenzierte Werk lediglich eine Komponente (von vielen) ist.
Zudem wäre es alles andere als zielführend, kommerzielle Weiterverwendung pauschal zu verurteilen. Was ist falsch daran, mithilfe externer Bestandteile ein neues Produkt zu bauen, welches eine zweckmäßige Lösung für ein reales Problem liefert, und einen finanziellen Ausgleich für die eigenen Mühen zu verlangen?
Wenn das Problem darin besteht, dass der Entwickler des Original-Quellcodes keinen Anteil am Gewinn erhält, dann lässt sich leicht entgegnen, dass er einerseits jederzeit sein eigenes Werk selbst monetarisieren kann und dass er andererseits immer die Möglichkeit hatte, das (abgeleitete) Werk des Lizenznehmers selbst zu realisieren. Es gibt keinen triftigen Grund, weshalb nur der ursprüngliche Urheber zu kommerzieller Verwertung berechtigt sein sollte.
Ist der Einwand jedoch, dass Profit allgemein unethisch sei, so muss die Antwort lauten, dass eine solche Haltung schlichtweg inkompatibel mit der modernen Gesellschaft ist. Jeder, der in der Lage sein möchte, Miete, Strom, Wasser, Gas und Rechnungen zu bezahlen, ist auf ein Einkommen angewiesen; die unrealistischen Vorstellungen einiger weniger Moralapostel können das nicht im Geringsten ändern.
Scraping ist nicht unethisch, sondern durch die Softwarefreiheit gedeckt
Darüber hinaus stellt sich die Frage, was unethisch daran ist, öffentlich zugängliche Werke durch eine „KI“ analysieren zu lassen. Unabhängig von der Tatsache, dass hier keine Urheberrechtsverletzung vorliegt, lässt sich nichts ethisch Fragwürdiges daran finden, wenn man bedenkt, dass das Studieren von Quellcode ein Grundbestandteil der Softwarefreiheit ist. Diejenigen, die GitHub dafür kritisieren, ihren Quellcode zu studieren, haben wohl vergessen, warum sie ihn überhaupt unter eine freie Lizenz gestellt haben. Als Erinnerung seien hier die vier Softwarefreiheiten genannt:
- Die Freiheit, das Programm auszuführen, wie man möchte, für jeden Zweck (Freiheit 0).
- Die Freiheit, die Funktionsweise des Programms zu untersuchen und eigenen Datenverarbeitungbedürfnissen anzupassen (Freiheit 1). Der Zugang zum Quellcode ist dafür Voraussetzung.
- Die Freiheit, das Programm zu weiterzuverbreiten und damit Mitmenschen zu helfen (Freiheit 2).
- Die Freiheit, das Programm zu verbessern und diese Verbesserungen der Öffentlichkeit freizugeben, damit die gesamte Gesellschaft davon profitiert (Freiheit 3). Der Zugang zum Quellcode ist dafür Voraussetzung. Free-Software-Foundation
Doppelte Standards in Bestform
Als völlig absurd muss benannt werden, dass Copyleft-Enthusiasten einerseits Nutzer ethischer Lizenzen (wie der For-Good-Eyes-Only-Lizenz) dafür kritisieren, beispielsweise keine Menschenrechtsverletzungen tolerieren zu wollen, und die Toleranz der Intoleranz propagieren, aber andererseits sofort empört reagieren, wenn jemand Missliebiges ihre Werke verwendet.
Copyleft fördert Monopole
Zusätzlich zu den zahlreichen rechtlichen Irrtümern vieler Entwickler zeigt die Copilot-Debatte, dass Copyleft-Lizenzierung zwar in gutem Glauben erfolgen mag, sie aber ihre Ziele nicht erreicht. Aufgrund der Tatsache, dass Copyleft die Weiterverbreitung des lizenzierten Werks ausschließlich unter derselben oder zumindest einer vergleichbaren Lizenz erlaubt, muss unvermeidlich gefragt werden, auf welcher rechtlicher Grundlage Lizenznehmer ihre abgeleiteten Werke auf Drittanbieter-Plattformen hochladen.
Natürlich haben sie das Recht dazu, ihre Forks zu veröffentlichen. Doch streng genommen, gewähren Copyleft-Lizenzen typischerweise nicht die Erlaubnis, etwaigen Code-Hosting-Anbietern die vollen Nutzungsrechte übertragen zu dürfen, wie es für GitHubs Nutzungsbedingungen erforderlich wäre. Um die Copyleft-Vorschriften zu erfüllen, müsste man eigentlich individuelle Vertragsbedingungen mit GitHub verhandeln, in denen die Einhaltung der ursprünglichen Lizenz durch GitHub geregelt würde.
Wer vermeiden will, eine Urheberrechtsverletzung zu begehen und sich eine Klage einzufangen, der sollte davon Abstand nehmen, Forks auf Drittanbieter-Plattformen zu veröffentlichen. Dies auf ein und derselben Plattform zu tun – also dort, wo das Originalwerk ohnehin bereits (durch dessen Autor) veröffentlicht wurde –, wäre andererseits unproblematisch; schließlich hätte der ursprüngliche Urheber dann schon selbst den Nutzungsbedingungen zugestimmt, weshalb eine Rechteeinräumung durch den Lizenznehmer keinen Unterschied bewirken würde.
Dieser Umstand leistet Monopolstellungen jedoch maßgeblich Vorschub, wie am Beispiel von GitHub zu erkennen ist. Möchte man auf GitHub veröffentlichte Copyleft-Software rechtssicher verwenden, ist man faktisch gezwungen, auch selbst GitHub anstelle einer anderen Plattform zu verwenden. Aufgrund dieser Tatsache muss deutlich ausgesprochen werden, dass Copyleft – im Gegensatz zu liberalerer Lizenzierung – massive rechtliche Probleme mit sich bringen kann und daher die Entwicklung freier Software unnötig behindert.
Natürlich kann argumentiert werden, dass jeder Entwickler nur seinen eigenen Git-Server hosten müsste, um das Drittanbieter-Problem zu umschiffen, doch das ist nichts als absurd, wenn man den unverhältnismäßigen Verwaltungsaufwand, nötige Expertise und hohe Mietkosten bedenkt.
Zudem muss bedacht werden: Diejenigen, die ihren Code unter eine Copyleft-Lizenz stellen, senden das politische Signal, dass sie die Softwarefreiheit unterstützen. Wer das tut, kann wohl kaum daran interessiert sein, andere davon abzuhalten, ihre Softwarefreiheiten auszuüben – indem ihnen verboten wird, den Quellcode bei Drittanbietern hochzuladen. Überdies sind die Nutzungsrechte, welche dem Hostinganbieter eingeräumt werden, meist darauf beschränkt, die angebotenen Dienste zu leisten. Relevant ist ebenfalls der Umstand, dass diese Art von Nutzungsbedingungen marktüblich ist; in diesem Sinne wären entsprechende Copyleft-Einschränkungen einerseits erwartbar und andererseits ertragbar.
Natürlich darf man sich auf diese Argumentation nicht verlassen, da das Weiterverbreiten eines Werks unter mit der Copyleft-Lizenz inkompatiblen Plattform-Nutzungsbedingungen eine Urheberrechtsverletzung ist und bleibt, solange es keine entsprechende gesetzliche Regelung oder zumindest Rechtsprechung gibt. Verschärfend darauf wirkt sich die Tatsache aus, dass freie Software häufig grenzüberschreitend verbreitet und verwendet wird, sodass keine einheitliche rechtliche Situation angenommen werden kann.
Softwarefreiheit meint (auch) Lizenzwahlfreiheit
Weiterhin korreliert die Durchsetzbarkeit von Urheberrechtsansprüchen auf Basis von Copyleft-Lizenzen direkt mit der Strenge des Urheberrechts: Copyleft entfaltet nur dank traditioneller Gesetzgebung irgendwelche Wirkung, obgleich es auf die Umgehung oder gar Abschaffung des Urheberrechts abzielt.
Softwarefreiheit sollte auch die Freiheit des Lizenznehmers beinhalten, seine Adaption des lizenzierten Werks dem Urheberrecht durch freie Lizenzierung zu entziehen. Copyleft-Bedingungen verbieten diese Freiheit, indem sie selbst vom Urheberrecht Gebrauch machen.
Strengeres Urheberrecht brächte ausschließlich Nachteile
Die Angelegenheit wird noch absurder, wenn Copyleft-Enthusiasten strengeres Urheberrecht fordern, nur um selbst die kleinsten Codeschnipsel in geistiges Eigentum verwandeln und zum Subjekt von Lizenzbedingungen machen zu können. Sie übersehen jedoch, dass Copyleft von vornherein nicht nötig wäre, wenn das Urheberrecht „nicht grundsätzlich ein so hohes Maß an exklusiver Kontrolle über geistige Schöpfungen garantieren würde“, wie Felix Reda es formuliert.
Wie er zurecht ausführt, würde strengeres Urheberrecht hauptsächlich bestehende Rechte stärken – und nicht das Copyleft-Prinzip. Presseverlage beispielsweise lobbyieren seit Langem für ein strengeres Leistungsschutzrecht, nach welchem sogar die Überschriften von Zeitungsartikeln – also die kürzestmöglichen Phrasen und Satzfragmente – urheberrechtlich geschützt wären. Das würde bedeuten, dass u.a. Suchmaschinen zahlen müssten, um Überschriften oder Beschreibungstexte in Suchergebnissen anzeigen zu dürfen.
Große Unternehmen wie Google, Meta oder Twitter können sich solche Zahlungen aus der Portokasse leisten; doch was ist mit nichtkommerziellen Diensten wie dem freien sozialen Medium Mastodon oder dem quelloffenen Signal-Messenger? Was ist mit XMPP- und E-Mail-Clients, die ein Freiwilliger mal eben in seiner Freizeit zusammenprogrammiert hat? Sie müssten auf so essenzielle Funktionen wie Linkvorschauen verzichten.
Im Januar 2022 entschied das Hamburger Landgericht (308 O 130/19 ), dass Browser-Adblocker „keine unberechtigte Vervielfältigung und/oder Umarbeitung von urheberrechtlich geschützten Computerprogrammen“ darstellen. Den Vorstellungen der Copyleft-Enthusiasten von strengerem Urheberrechtsschutz entsprechend, könnte es daher zukünftig durchaus verboten sein, Software zum Schutz vor übergriffiger Werbung und Privatsphäre-verletzenden Trackern einzusetzen.
Wie Werke stattdessen lizenziert werden sollten
Copyleft bringt lediglich ungebetene Probleme mit sich. Seine Durchsetzbarkeit erfordert strengeres Urheberrecht, schränkt die Lizenznehmer in ihrer Softwarefreiheit ein und verursacht schwerwiegende rechtliche Probleme beim Erstellen von Forks.
Stattdessen sollte eine der konventionellen liberaleren Lizenzen verwendet werden, wie z.B. die MIT-Lizenz. Nicht nur ist sie sehr leicht zu verstehen, sondern sie lässt dem Lizenznehmer hinreichende Freiheiten bei der Relizenzierung.
Für all jene, die sich ihrer Verantwortung als Softwareentwickler stellen und ein Zeichen gegen Ungerechtigkeit in der Welt setzen wollen, gibt es die Option ethischer Lizenzierung. Zusätzlich zum Offensichtlichen, d.h. Kriegsverbrechen und Menschenrechtsverletzungen, verbietet beispielsweise die For-Good-Eyes-Only-Lizenz auch Datenschutzverstöße oder Fake-News und schließt Umweltsünder von der Weiterverwendung aus.
Ein wesentlicher Vorteil der For-Good-Eyes-Only-Lizenz besteht darin, dass sie keine Copyleft-Klausel beinhaltet. Um die ethischen Verhaltensregeln auch gegen Dritt-/Sublizenznehmer durchsetzen zu können, müssen die Komponenten des Originalwerks stets unter der ursprünglichen Lizenz verbleiben (und dürfen nicht relizenziert werden); doch für eigene Änderungen und Einfügungen darf der Lizenznehmer jede x-beliebige Lizenz zur Weiterverbreitung wählen. Diese Regelung nennt sich „schwaches Copyleft“ und basiert lose auf der Mozilla-Public-Licence.
Warum #GiveUpGitHub dennoch sinnvoll ist
Entgegen der absurden, unrealistischen Dämonisierung der Copilot-Funktion muss zusammenfassend festgestellt werden, dass die generelle Kritik an GitHub als Hostinganbieter gerechtfertigt ist – aus nachfolgenden vier Gründen.
- Es ergibt keinerlei Sinn, eine proprietäre Plattform für freie Software zu verwenden. Wir sollten uns vielmehr für die Verbreitung freier Software einsetzen; dies können wir tun, indem wir bereits bei der Entwicklung unserer Werke freie Werkzeuge verwenden.
- Es ist alles andere als vernünftig, die Existenz eines so mächtigen Quasi-Monopols wie GitHub zuzulassen. Was würden wir tun, sollte Microsoft über Nacht GitHub einstampfen? Viele Menschen würden sicherlich ins Schwitzen kommen, wäre GitHub bereits für wenige Stunden aufgrund eines Stromausfalls o.ä. nicht erreichbar. Außerdem eröffnet ein Monopol potenziell Möglichkeiten der Zensur.
- Wir schließen all jene davon aus, zu unserer freien Software beizutragen, die – aus welchen Gründen auch immer – nicht in der Lage oder nicht willens sind, sich bei GitHub zu registrieren. Manche mögen von restriktiver US-Export-Reglementierung betroffen sein, andere fürchten um ihre Privatsphäre.
- Das Mutterunternehmen von GitHub, Microsoft, ist ein skrupelloser Hersteller von Werbetracking-Schadsoftware und ein moralbefreiter Kollaborateur der US-Geheimdienste. Wir sollten jene unethischen Praktiken nicht unterstützen, indem wir Microsofts Produkte verwenden.
Stattdessen sollten wir uns auf Gitlab - oder Forgejo -Servern registrieren: Beide Plattformen sind selbst quelloffen. Das ermöglicht datenschutzfreundliches und zensurresistentes Self-Hosting. Je mehr Entwickler gewillt sind, GitHub zu verlassen, desto mehr öffentliche Gitlab- und Forgejo-Server werden eröffnet werden. Zudem ist man bei Forgejo bereits damit beschäftigt, einen Standard zu entwickeln, der Kommunikation zwischen Git-basierten Code-Hosting-Servern regeln soll (analog zu E-Mail oder ActivityPub). Dank solcher Föderation müsste man sich nur auf einer einzigen Plattform registrieren und könnte dennoch zu allen Git-Repos auf all den anderen Servern beitragen.
Ganz besonders empfohlen sei der deutsche Git-Server Codeberg , dessen wesentlicher Vorteil gegenüber anderen Anbietern die Codeberg-Pages -Funktion ist – ein fantastischer Ersatz für GitHub Pages.
Es bleibt zu hoffen, dass so bald als möglich ein umfassendes Umdenken in der Freie-Software-Gemeinschaft stattfinden und dass man endlich verstehen wird, wie absurd es ist, dass das essenzielle Werkzeug unseres Zusammenarbeitens selbst keine freie Software ist.
 Optimiert für
Mozilla Firefox
Optimiert für
Mozilla Firefox
 Verzwiebeln mit dem
Tor Hidden Service
Verzwiebeln mit dem
Tor Hidden Service
 Folge auf
Mastodon
Folge auf
Mastodon
 Bitte spende
gegen den Krieg
Bitte spende
gegen den Krieg

